
Of course we cannot always share details about our work with customers, but nevertheless it is nice to show our technical achievements and share some of our implemented solutions.
The Kubernetes cluster is a complex world patched together from all kinds of resources and dependencies. This includes Ingresses (Nginx, Traefik, HAProxy, etc), lots of Firewall rules (iptables/netfilter), Helm charts, Cgroups, container images, deployment manifests, network (ports) connectivity between the nodes and many other dependencies. Last, but not least, the underlying Operating System Kernel provides the needed functions to get a K8s cluster running.
But sometimes one small bug in just one resource can cause troubles in the whole cluster. This blog post is about such a case.
All our managed Kubernetes clusters are monitored. As we are currently using SUSE Rancher as Kubernetes management, we use the check_rancher2 monitoring plugin to monitor the cluster itself, the nodes and the deployed workloads. All the clusters are fully integrated into our Icinga monitoring.
Then, one morning, we got the alert, that one downstream cluster has an issue and went into "unavailable" state.

The most common reason is that one or multiple nodes of the affected cluster ran into a "Node Pressure" situation. A MemoryPressure or DiskPressure situation causes Kubernetes to kill pods. If by chance (or better said bad luck) this pod is the pod responsible for communication with the Rancher Server, the communication between Rancher and the downstream cluster will be temporarily unavailable.
But after quickly verifying the Pressure situation and the usage of the Kubernetes Nodes, all seemed good. The Nodes themselves showed no signs of problems.
After a closer look into the downstream cluster, it seemed like the kube-proxy pod on a particular node had an issue. The kube-proxy pods are redundantly deployed across all cluster nodes. Only one of the pods had an issue, never successfully completing the Readyness check.
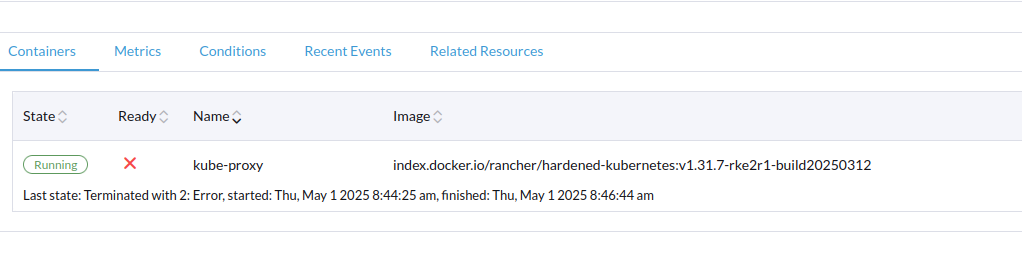
A look into the pod logs showed a problem with the iptables-restore command, which was attempted to run by the kube-proxy pod:
ck@infiniroot ~ $ kubectl logs kube-proxy-nodexyz -n kube-system
I0502 07:37:27.835881 1 server.go:677] "Successfully retrieved node IP(s)" IPs=["172.17.20.133"]
E0502 07:37:27.836311 1 server.go:234] "Kube-proxy configuration may be incomplete or incorrect" err="nodePortAddresses is unset; NodePort connections will be accepted on all local IPs. Consider using `--nodeport-addresses primary`"
I0502 07:37:28.019056 1 server.go:243] "kube-proxy running in dual-stack mode" primary ipFamily="IPv4"
I0502 07:37:28.019190 1 server_linux.go:169] "Using iptables Proxier"
I0502 07:37:28.024750 1 proxier.go:255] "Setting route_localnet=1 to allow node-ports on localhost; to change this either disable iptables.localhostNodePorts (--iptables-localhost-nodeports) or set nodePortAddresses (--nodeport-addresses) to filter loopback addresses" ipFamily="IPv4"
I0502 07:37:28.025809 1 server.go:483] "Version info" version="v1.31.7+rke2r1"
I0502 07:37:28.025883 1 server.go:485] "Golang settings" GOGC="" GOMAXPROCS="" GOTRACEBACK=""
I0502 07:37:28.030738 1 config.go:199] "Starting service config controller"
I0502 07:37:28.030840 1 shared_informer.go:313] Waiting for caches to sync for service config
I0502 07:37:28.031168 1 config.go:105] "Starting endpoint slice config controller"
I0502 07:37:28.031192 1 shared_informer.go:313] Waiting for caches to sync for endpoint slice config
I0502 07:37:28.032139 1 config.go:328] "Starting node config controller"
I0502 07:37:28.032167 1 shared_informer.go:313] Waiting for caches to sync for node config
I0502 07:37:28.131151 1 shared_informer.go:320] Caches are synced for service config
I0502 07:37:28.132391 1 shared_informer.go:320] Caches are synced for node config
I0502 07:37:28.132507 1 shared_informer.go:320] Caches are synced for endpoint slice config
[...]
E0502 07:39:28.770387 1 proxier.go:1564] "Failed to execute iptables-restore" err=<
exit status 2: Warning: Extension MARK revision 0 not supported, missing kernel module?
ip6tables-restore v1.8.9 (nf_tables): unknown option "--xor-mark"
Error occurred at line: 17
Try `ip6tables-restore -h' or 'ip6tables-restore --help' for more information.
> ipFamily="IPv6"
I0502 07:39:28.770442 1 proxier.go:833] "Sync failed" ipFamily="IPv6" retryingTime="30s"
After a couple of minutes research, Ubuntu bug #2091990 was found, mentioning the same error as seen inside the kube-proxy pod:
> Errors like below can be seen in these jobs
(4, ('', 'ip6tables-restore v1.8.7 (nf_tables): unknown option "--set-xmark"\nError occurred at line: 26\nTry `ip6tables-restore -h\' or \'ip6tables-restore --help\' for more information.\n', 2)) {{(pid=56448)
The bug was reported against the Kernel package (5.15.0) of the older Ubuntu 22.04 (Jammy) LTS version. The Kubernetes Nodes in question run the latest Ubuntu 24.04 (Noble) LTS.
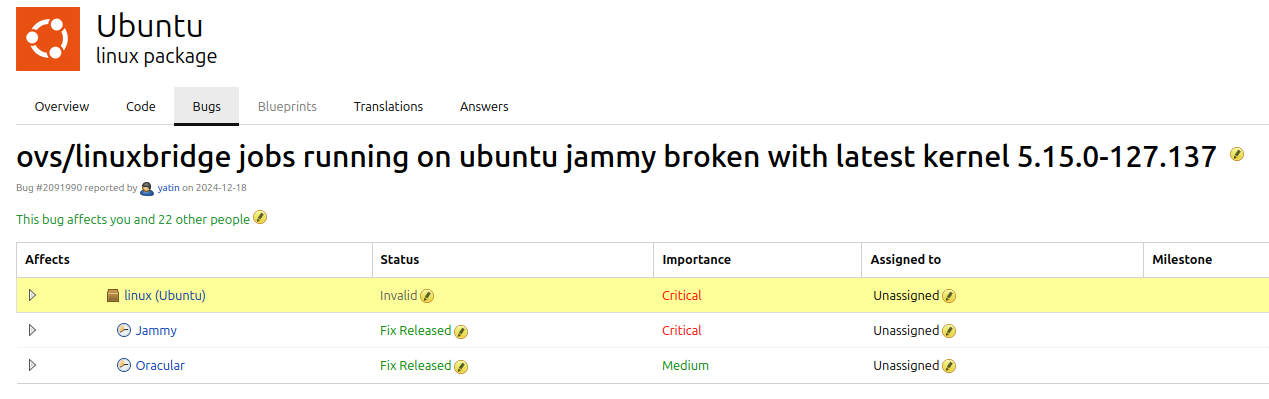
Although the bug's meta data did not mention the "noble" release, another user confirmed that the Kernel (6.8.0) in Noble is affected, too:
> This issue is also now in noble numbat. Just upgraded from 6.8.0-55-generic to 6.8.0-57-generic and is getting the following error in kube-proxy:
exit status 2: Warning: Extension MARK revision 0 not supported, missing kernel module?
ip6tables-restore v1.8.9 (nf_tables): unknown option "--xor-mark"
Error occurred at line: 17
Try `ip6tables-restore -h' or 'ip6tables-restore --help' for more information.
Another bug report was created in Rancher's RKE2 project. However this one was (correctly) closed and mentioned that this is an upstream bug and can't be fixed in RKE2:
This bug is present in Ubuntu Noble's 6.8.0-56-generic kernel.
A quick verification on the Kubernetes Nodes confirmed the affected Kernel version is indeed installed:
root@nodexyz:~# uname -a
Linux nodexyz 6.8.0-57-generic #59-Ubuntu SMP PREEMPT_DYNAMIC Sat Mar 15 17:40:59 UTC 2025 x86_64 x86_64 x86_64 GNU/Linux
At this point we were "relieved". We knew the source of the problem and knew how to fix it, by upgrading the Kernel. However which Kernel patch update would contain the fix?
As it turns out, the bug was fixed in the Linux Kernel upstream project already a while ago (in October 2024).
Unfortunately the Ubuntu Linux package changelog is pretty vague when this bugfix made it into the update. From our best guess the fix was added in version 6.8.0-58.60, released at the end of March 2025. The changelog mentions this fix:
netfilter: xtables: fix typo causing some targets not to load on IPv6
Unfortunately without a reference to an Ubuntu Launchpad (LP) bug.
One user confirmed in a related Ubuntu bug #2101914 that the bug is fixed with 6.8.0-58:
OK, can confirm issue is resolved in 6.8.0-58-generic (6.8.0-58.60+1)
The Kernel bug fix showed that typo was fixed in the netfilter Kernel module:
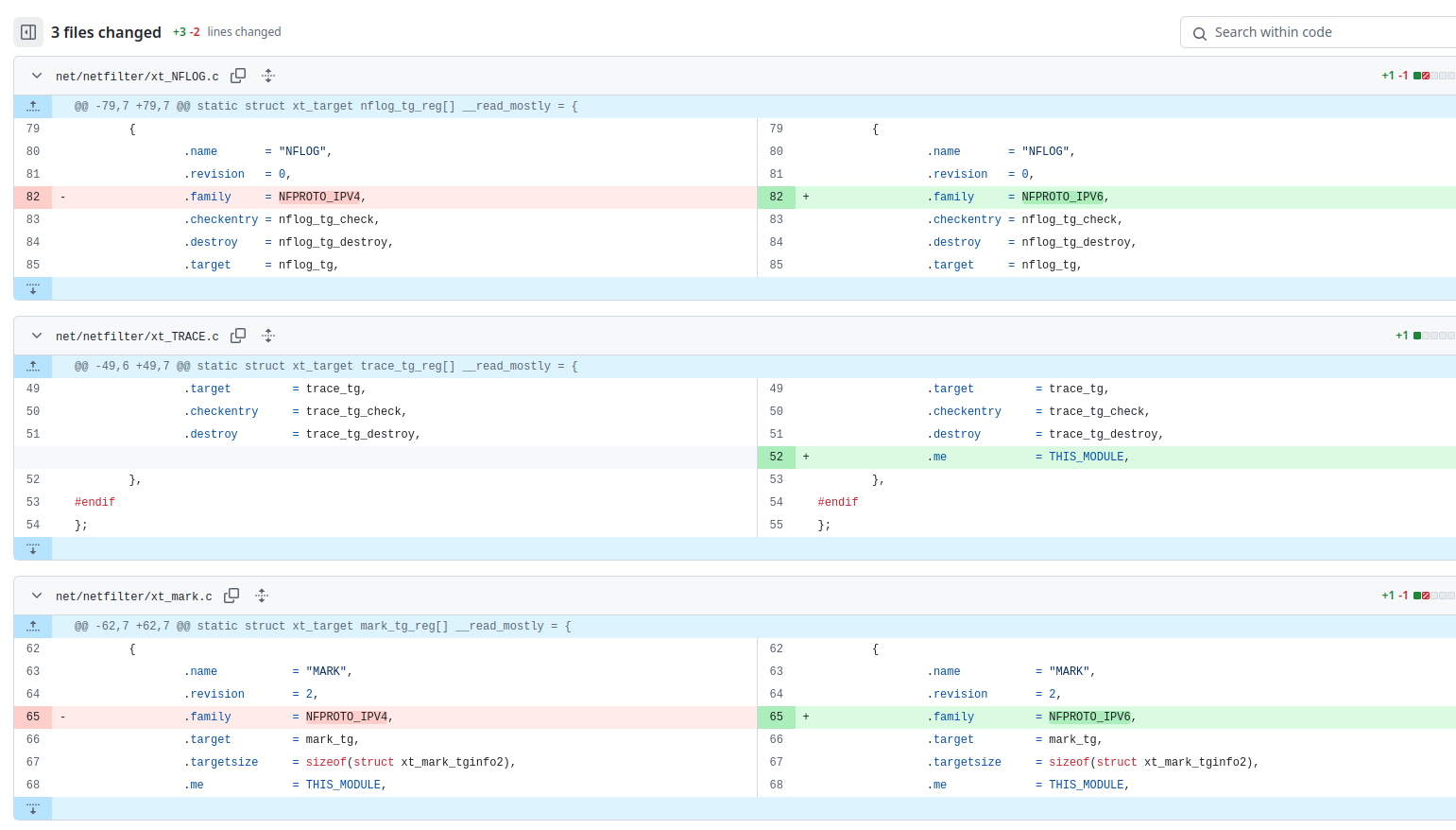
Bugs like this can happen. They can go through all kinds of QA tests, but something is always forgotten or not thought of. This can happen, especially in the Open Source world we love.
But this bug is a very good reminder that modern (web-) infrastructures are built on complex systems (such as Kubernetes) which themselves rely on lower level resources and dependencies. If just one of these puzzle pieces breaks apart, your application can run into problems.
The following XKCD drawing perfectly describes the situation. And there's no better way to end this post with this drawing.

We at Infiniroot love to share our troubleshooting knowledge when we need to tackle certain issues - but we also know this is not for everyone ("it just needs to work"). So if you are looking for a managed Rancher Kubernetes cluster in Switzerland or even in your own on-premise data center, check out our Private Kubernetes Cloud Infrastructure service at Infiniroot. We take care of the technical challenges - and you can focus on your application and deployment.